Slowdown and memory leak in ConcurrentLinkedQueue
Yesterday, I stumpled upon a rather interesting memory leak in Java’s ConcurrentLinkedQueue, I’d like to share with you.
What is this all about
The ConcurrentLinkedQueue leaks memory and slows down when removing the last element of a non-empty queue.
Reproducing the problem
So to reproduce the leak, we must constantly add and try to remove the last item of an initially filled queue. The following code is showing the problem quite well as it prints the duration it takes for every 10.000 iterations of adding and removing an object to the queue.
import java.util.concurrent.ConcurrentLinkedQueue;
public class TestLeak
{
public static void main(String[] args)
{
ConcurrentLinkedQueue<Object> queue = new ConcurrentLinkedQueue();
queue.add(new Object()); //Required for the leak to appear.
Object object = new Object();
int loops = 0;
long last=System.currentTimeMillis();
while(true)
{
if(loops%10000==0)
{
long now = System.currentTimeMillis();
long duration = now - last;
last=now;
System.err.printf("loops=%d duration=%d%n",loops, duration);
}
queue.add(object);
queue.remove(object);
++loops;
}
}
}
When running the code snippet it shows that after only 60.000 iterations it already takes one second to add and remove the object 10.000 times.
| Total iterations | Duration (in ms) |
| 0 | 0 |
| 10000 | 125 |
| 20000 | 289 |
| 30000 | 478 |
| 40000 | 666 |
| 50000 | 849 |
| 60000 | 1056 |
Okay, that’s the slowdown. Up next is the memory leak we’re going to prove. To show you this, I did a 30 minutes flight recording via the Oracle Java Mission Control. There is actually a good tutorial by Oracle how to do that, so I won’t go into detail on this one. When doing this flight recording, you can enable some heap (graphic below) statistics that will show you how much space the Old Generation is taking inside the heap at the start and the end of the recording. The old generation is used to store long surviving objects. So the old generation is also the place, where leaks manifest most of the time when the (expensive and stop-the-world) Garbage-Collector isn’t able to clean things up in this space.
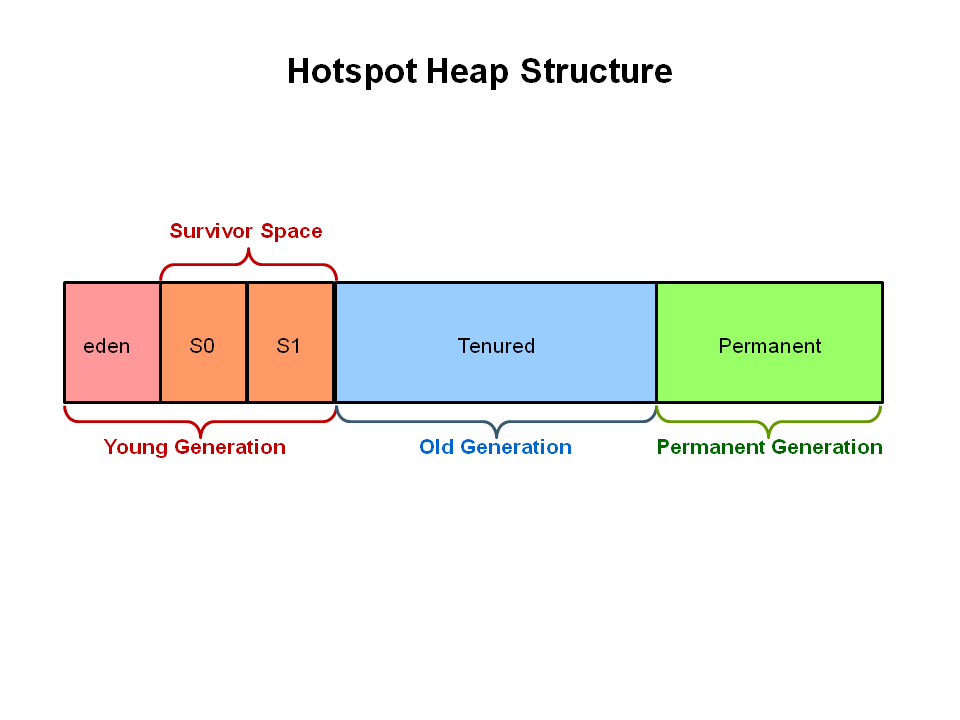
When looking at the first and last garbage collection inside the old generation of my flight recording, I got the following results, which clearly indicate a memory-leak:
| Start | End | |
| Heap-Usage after GC | 1,54 MB | 28,60 MB |
|---|
Explanation of the problem
To explain the problem I want to start of with a little reminder on the basics of the ConcurrentLinkedQueue.
Taken from the official docs
An unbounded thread-safe queue based on linked nodes. This queue orders elements FIFO (first-in-first-out). The head of the queue is that element that has been on the queue the longest time. The tail of the queue is that element that has been on the queue the shortest time. New elements are inserted at the tail of the queue, and the queue retrieval operations obtain elements at the head of the queue…
What it essentially is
The queue is a list of nodes. Each node holds its object plus a reference to the next node, that can be accessed via .next(). If it’s the last node, this will be null though. The queue itself holds a reference to the first node that can be accessed via first().
As usual with the official docs, the real meat is a bit hidden between the lines. If you want to remove an object from the queue the links between the nodes need to be adjusted, of course. So when removing a node, it needs to start from the head to the tail for this kind of operation as you see below in the official code.
public boolean remove(Object o) {
if (o == null) return false;
Node pred = null;
for (Node p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null
&& o.equals(item)
&& p.casItem(item, null)) { // p.casItem() will try to null the item
Node next = succ(p); //Get next-pointer of current node
if (pred != null && next != null)
pred.casNext(p, next); // Try to delink the next-pointer of the previous node
return true;
}
pred = p;
}
return false;
}
I commented the code a bit to hopefully make it more clear what actually happens. The remove code nulls the item value via p.casItem(item, null) and then should attempt to delink the predecessor’s next-pointer to bring things back to order. However, if the current node next-pointer is null (which it is for the last item), then the predecessor node’s next-pointer is not nulled. Thus the last node instance is never really removed and the queue grows until eventually there isn’t any memory left. As more and more nodes are appended, each further add+remove operation will have to navigate the linked list until the end, which results in a higher CPU consumption and a slowdown of performance.A fixed version is already committed, but I don’t know in which JVM versions this will be available:
public boolean remove(Object o) {
if (o != null) {
Node next, pred = null;
for (Node p = first(); p != null; pred = p, p = next) {
boolean removed = false;
E item = p.item;
if (item != null) {
if (!o.equals(item)) {
next = succ(p);
continue;
}
removed = casItem(p, item, null);
}
next = succ(p);
if (pred != null && next != null) // unlink
casNext(pred, p, next);
if (removed)
return true;
}
}
return false;
}
Closing thoughts
Long story, short. The reason I’m telling you this is the fact that some of us are using Jetty as their webserver. Jetty is using the ConcurrentLinkedQueue in its QueuedThreadPool that could potentially lead to this leak, but more importantly to the slowdown. In general this thread-pool tries to reuse its threads, but it can happen that a thread is dying and needs to be respawned. So depending on the pools thread death-rate (say this 3 times in a row), you will be more or less affected by the bug above. Their workaround for now is to use their ConcurrentHashSet class. To give you some insights on what this potentially means in terms of performance, here are some numbers for 100 mio. of iterations:
| ConcurrentHashSet | ConcurrentLinkedQueue | |
| Time taken per 100 mio. iterations | 5 seconds | Aborted after 30 minutes without completion |
|---|
Note: A quick load test in our app showed that we’re not affected by this bug as an upgrade to Jetty http://mvnrepository.com/artifact/org.eclipse.jetty/jetty-server/9.3.4.RC1 didn’t had any benefit. Somehow expected because we would have seen this earlier. But to be honest I hoped a bit that we were affected ![]() .
.
Relevant links
https://bugs.openjdk.java.net/browse/JDK-8137184
https://bugs.eclipse.org/bugs/show_bug.cgi?id=477817
https://github.com/eclipse/jetty.project/commit/3c4eb5c4f6432ce508aad00a82c1cf62d3ae035d


We monitored system for approx one month and the memory footprint is consistent. Thanks the8472 for guiding me in right direction
Our sysadmin has been doing drain just before restarting, but it is not periodic. The only periodic crontab command is a weekly repair of each node, done in a rolling fashion. We looked for correlation with this memory leak problem and found none. Is there something else that would cause this drain-like behavior?